Open-source contribution as a student project
An opportunity to teach, an opportunity to give back…
If you’ve seen one of my data science education talks or attended one of my workshops in the last few years, you’ve probably heard me talk about the unvotes package in R.
This package provides the voting history of countries in the United Nations General Assembly, along with information such as date, description, and topics for each vote.
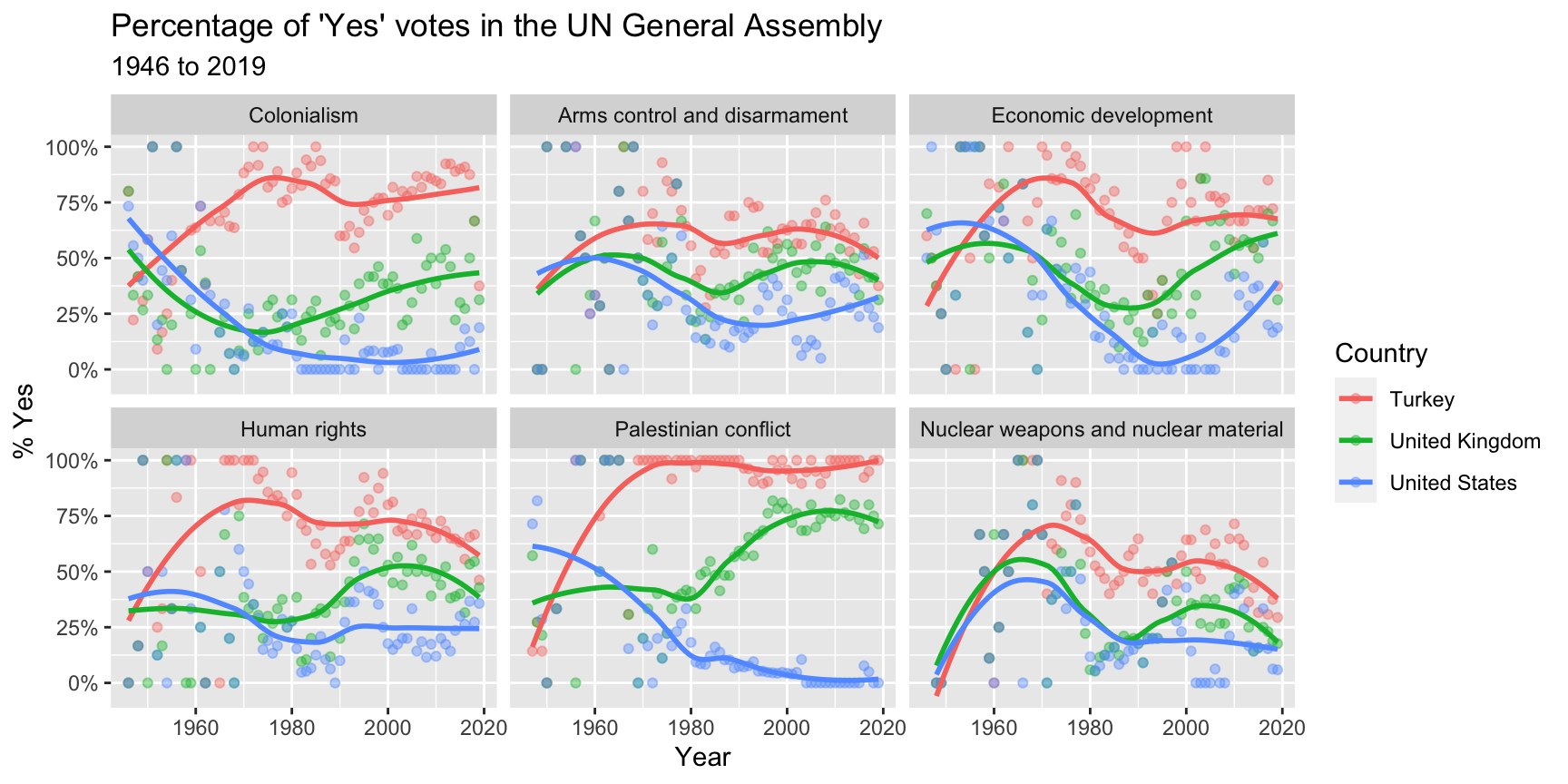
I love using data from this package in my teaching, especially on day one of class, because the data are rich while being accessible. An activity I use on the first day of class is reproducing the following visualization based on an R Markdown document containing the complete code for creating this visualization and then making one change to it (changing one of the countries plotted). If you’d like to try out this activity yourself, you can do so on the RStudio Cloud space for Data Science in a Box – click here to join the space and start the project titled AE 01a - UN Votes.
I’ve had it in the back of my mind to send in a pull request to update this package for over a year now, but somehow I never managed to make time to do that.
At the end of the last semester, on the last video of my Introduction to Data Science course, I told my students I’d be happy to work with them on a project the following semester. One of the projects I had in mind was updating this package. One of my students, Nicholas Goguen-Compagnoni, expressed interest in this project and now he’s a contributor to the package!
This blog post is a story of how we structured this project. I hope it might be helpful to those considering structuring student projects, independent studies, etc. around open-source contributions to R packages.
Background
But first, I should give a little bit of background on what students did (and did not) learn in my course, so you can have a better sense of the preparation level of the student starting to work on such a project.
- Students in my Introduction to Data Science course learn R using RStudio.
- They do most of their work in R Markdown documents but they also learn to use R scripts, particularly to scrape and clean data and write it out to a csv to be used subsequently in an analysis completed in an R Markdown document.
- They learn what R packages are but not how to make them, or what their internals look like.
- They learn to work with Git and GitHub, specifically committing, pushing, pulling, and resolving merge conflicts. They don’t learn about branches or pull requests.
- They don’t learn to write tests.
- They are aware of GitHub actions as this is how they get immediate feedback on their work. They know where to go to view the log for an action that failed, but can’t always figure out what the next steps should be for resolving the issue. (Frankly, my success rate on that is not 100% either…)
Structuring the project
With this background in mind, here is how we structured the project. Note that we did some of these steps simultaneously as we broke the project down into weekly chunks.
Step 1. Assess feasibility
The first “homework” was to figure out if it’s even feasible to update the package, which would mean finding more recent data on United Nations voting history.
The package GitHub repo included a data-raw folder, and linked to the data source on the README of that folder. This was super helpful as a starting point. We were able to locate more updated data at the same location, so we didn’t need to do much digging.
Step 2. Assess interest
I am not the maintainer of the unvotes package, so I couldn’t really just decide that we were going to update the data on the original package. So we opened an issue on the package repo asking if the package maintainer, David Robinson, would be interested in a pull request. He responded favorably, so that was our green light!
As an aside, my backup plan was to fork the repo and update my fork only and use that in future teaching, but I was secretly really hoping that this would be a welcome update as I really didn’t want to use a version of a package for teaching different than its CRAN version.
Step 3. Learn about packages
I honestly can’t take any credit for this. I asked my Nicholas to read the Whole Game chapter of the R Packages book by Hadley Wickham and Jenny Bryan. It’s such a great introduction! I highly recommend this chapter to anyone who is just starting off with making R packages or those who might have been doing this for a while but want to try it out using “modern conveniences in the devtools package and the RStudio IDE”.
Step 4. Learn about pull requests
At this point I exclusively use a workflow that involves functions from the usethis package for pull requests so I also asked Nicholas to read the setup instructions for usethis, which helps you set up your GitHub credentials, as well as the pull request helpers vignette.
Step 5. Practice
Since I don’t maintain the unvotes package, I thought it would be better for my student’s first pull request to one of my repositories. I also wanted the practice experience to be as close to the real task as possible, which meant making a pull request to an R package.
One of the packages I maintain is openintro and we had a documentation related issue sitting there for a while. So I asked Nicholas to work on that issue following the workflows he recently learned about and to make a pull request. Then, in our next meeting, I reviewed the pull request while sharing my screen and talking through my feedback as I put it in. After our meeting Nicholas took another few days to work through the review comments and we successfully merged the pull request and closed the issue.
I think this step was very productive for both of us. It gave me a good idea of the concepts that were clear from the reading and those that needed more explanation and it allowed my student to submit a pull request without too much worry since I assured him numerous times that we can always start over together.
Step 6. Make the actual pull request
Well, kinda…
The next step was to work on the actual problem (updating the data) but we weren’t quite ready to make the actual pull request yet.
Nicholas forked the unvotes repo and worked on the data update on a branch, documenting his steps in the data-raw folder. Once done, he put in a pull request to his own repo’s main branch. And on our weekly call we worked through this pull request together, identifying any potential changes that needed to me made before issuing the actual pull request. We also ran some tests on the data to figure out whether any of the historical data had changed – and indeed it had! So we made a note of that to mention in the package pull request so that the package maintainer could decide how they wanted to proceed with that.
Step 7. Make the actual pull request, for real
Finally, Nicholas put in the pull request to the original unvotes repo and after a round of review and some edits by David, the package was ready to go!
The updated is package is now on CRAN. You can install it with install.packages(unvotes) and play with United Nations voting data up to 2019. In fact, thanks to David’s initiative, it’s going to be the #TidyTuesday dataset for this week!
Reflection
This project was very fun for me to work on for a variety of reasons. I love working with students and, as someone who tends to teach larger courses, don’t end up having many opportunities to work one-on-one with them. I also had been meaning to work on this for a while, but it kept dropping off my priority list, and finally it got done! Not only was this an opportunity to contribute back to an open-source project that I benefited so much from, it was also a great way to turn this into an educational project!
And it sounds like Nicholas enjoyed the experience too! Here is his reflection in his own words:
It was exciting to help update the unvotes package! First, I practiced updating one of Professor Çetinkaya-Rundel’s repositories. That part of the process let me practice all of the steps of a pull request on GitHub and learn what the CRAN standards for a package were. After the practice, I dove straight into the unvotes package. Professor Çetinkaya-Rundel and I would have a weekly meeting to discuss the specific steps for updating the package, and after the meeting, I would work on that part. Some steps we discussed were finding the updated data, cleaning the data to look like the old data, and briefing the package owner about any significant changes we made to the R script. Having Professor Çetinkaya-Rundel walk me through the steps was very helpful since I had not done very much coding before starting university, and I am grateful that she was kind enough to help me to learn beyond the classroom and give a guided, real world problem for me to help solve.
What’s next?
Next, we’re working on updating the data in the ukbabynames package. Since I maintain this package, we’ll be able to work through the final step of package development (submission to CRAN) together as well.
